


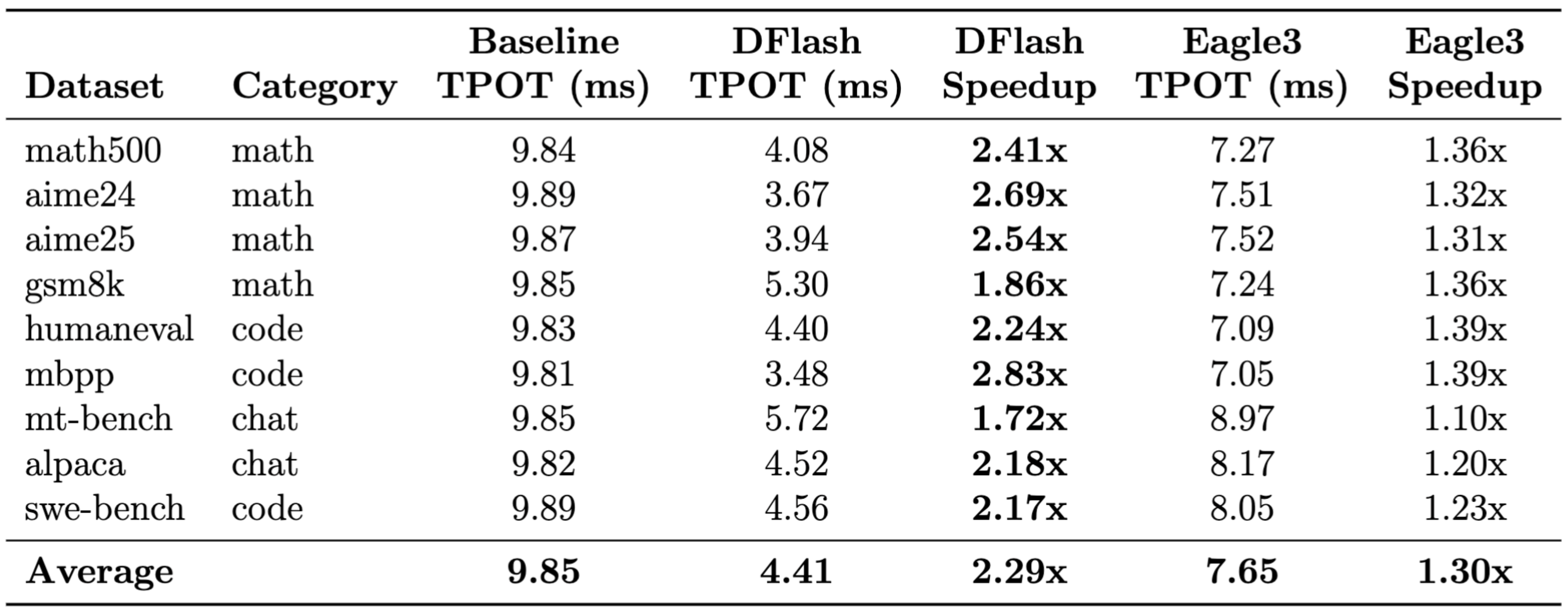
Researchers at UCSD have successfully implemented DFlash, a block-diffusion speculative decoding method, on Google TPUs to bypass the sequential bottlenecks of traditional autoregressive drafting. By « painting » entire blocks of candidate tokens in a single forward pass rather than predicting them one-by-one, the system achieved average speedups of 3.13x, with peak performance nearly doubling that of existing methods like EAGLE-3. This open-source integration into the vLLM ecosystem optimizes TPU hardware by leveraging « free » parallel verification and high-quality draft predictions for complex reasoning tasks.