


L’exactitude des prévisions météorologiques a un impact direct sur nos vies, qu’il s’agisse de nous aider à préparer nos activités quotidiennes ou de nous alerter face à des conditions météorologiques dangereuses. L’importance de prévisions précises et opportunes ne fera qu’augmenter avec le changement climatique. Chez Google, nous investissons dans la recherche sur la météorologie et le climat afin de garantir que les technologies de prévision de demain répondent à la demande d’informations météorologiques fiables. Parmi nos innovations récentes figurent MetNet-3, les prévisions haute résolution de Google jusqu’à 24 heures à l’avance, et GraphCast, un modèle météorologique capable de prédire la météo jusqu’à 10 jours à l’avance.
Par nature, la météo est stochastique. Pour quantifier l’incertitude, les méthodes traditionnelles reposent sur des simulations basées sur la physique pour générer un ensemble de prévisions. Cependant, il est coûteux de générer un vaste ensemble permettant de discerner et de caractériser avec précision les phénomènes météorologiques rares et extrêmes.
C’est dans cette optique que nous sommes ravis d’annoncer notre dernière innovation conçue pour accélérer les progrès dans les prévisions météorologiques : le **Scalable Ensemble Envelope Diffusion Sampler** (SEEDS), récemment publié dans _Science Advances_**. SEEDS est un modèle d’IA générative qui peut générer efficacement des ensembles de prévisions météorologiques *à grande échelle* à une fraction du coût des modèles de prévision physiques traditionnels. Cette technologie ouvre de nouvelles perspectives pour la science météorologique et climatique, et représente l’une des premières applications de modèles de diffusion probabilistes aux prévisions météorologiques et climatiques, une technologie d’IA générative à l’origine des récentes avancées en matière de génération de médias.
**La nécessité de prévisions probabilistes : l’effet papillon**
En décembre 1972, lors du congrès de l’**American Association for the Advancement of Science** à Washington, D.C., Ed Lorenz, professeur de météorologie au MIT, a donné une conférence intitulée « Does the Flap of a Butterfly’s Wings in Brazil Set Off a Tornado in Texas? » (« Le battement d’ailes d’un papillon au Brésil peut-il déclencher une tornade au Texas ? »), qui a contribué au terme « **effet papillon** ». Il se basait sur son article historique de 1963, où il examinait la faisabilité d’une « prévision météorologique à très long terme » et décrivait comment les erreurs dans les conditions initiales croissent exponentiellement lorsqu’elles sont intégrées dans le temps à l’aide de modèles de prévision météorologique numérique. Cette croissance exponentielle des erreurs, connue sous le nom de chaos, entraîne une limite de prévisibilité déterministe qui restreint l’utilisation des prévisions individuelles dans la prise de décision, car elles ne quantifient pas l’incertitude inhérente aux conditions météorologiques. Ceci est particulièrement problématique lorsqu’il s’agit de prévoir des phénomènes météorologiques extrêmes, tels que les ouragans, les vagues de chaleur ou les inondations.
Reconnaissant les limites des prévisions déterministes, les agences météorologiques du monde entier publient des **prévisions probabilistes**. Ces prévisions sont basées sur des ensembles de prévisions déterministes, chacune étant générée en incluant un bruit synthétique dans les conditions initiales et une stochasticité dans les processus physiques. En exploitant le taux de croissance rapide des erreurs dans les modèles météorologiques, les prévisions d’un ensemble sont volontairement différentes : les incertitudes initiales sont ajustées pour générer des résultats aussi différents que possible et les processus stochastiques dans le modèle météorologique introduisent des différences supplémentaires pendant l’exécution du modèle. La croissance des erreurs est atténuée en faisant la moyenne de toutes les prévisions de l’ensemble et la variabilité de l’ensemble de prévisions quantifie l’incertitude des conditions météorologiques.
Bien qu’efficaces, la génération de ces prévisions probabilistes est coûteuse en termes de calcul. Elles nécessitent de faire fonctionner des modèles météorologiques numériques très complexes sur des supercalculateurs massifs à plusieurs reprises. Par conséquent, de nombreuses prévisions météorologiques opérationnelles ne peuvent se permettre de générer que ~10–50 membres d’ensemble pour chaque cycle de prévision. C’est un problème pour les utilisateurs concernés par la probabilité de phénomènes météorologiques rares mais à fort impact, qui nécessitent généralement des ensembles beaucoup plus importants pour être évalués au-delà de quelques jours. Par exemple, un ensemble de 10 000 membres serait nécessaire pour prévoir la probabilité d’événements ayant une probabilité de survenue de 1 % avec une erreur relative inférieure à 10 %. Quantifier la probabilité de tels événements extrêmes pourrait être utile, par exemple, pour la préparation à la gestion des urgences ou pour les négociants en énergie.
**SEEDS : Progrès basés sur l’IA**
Dans l’**article** susmentionné, nous présentons le Scalable Ensemble Envelope Diffusion Sampler (SEEDS), une technologie d’IA générative pour la génération d’ensembles de prévisions météorologiques. SEEDS est basé sur des modèles probabilistes de diffusion de débruitage, une méthode d’IA générative de pointe pionnière en partie par Google Research.
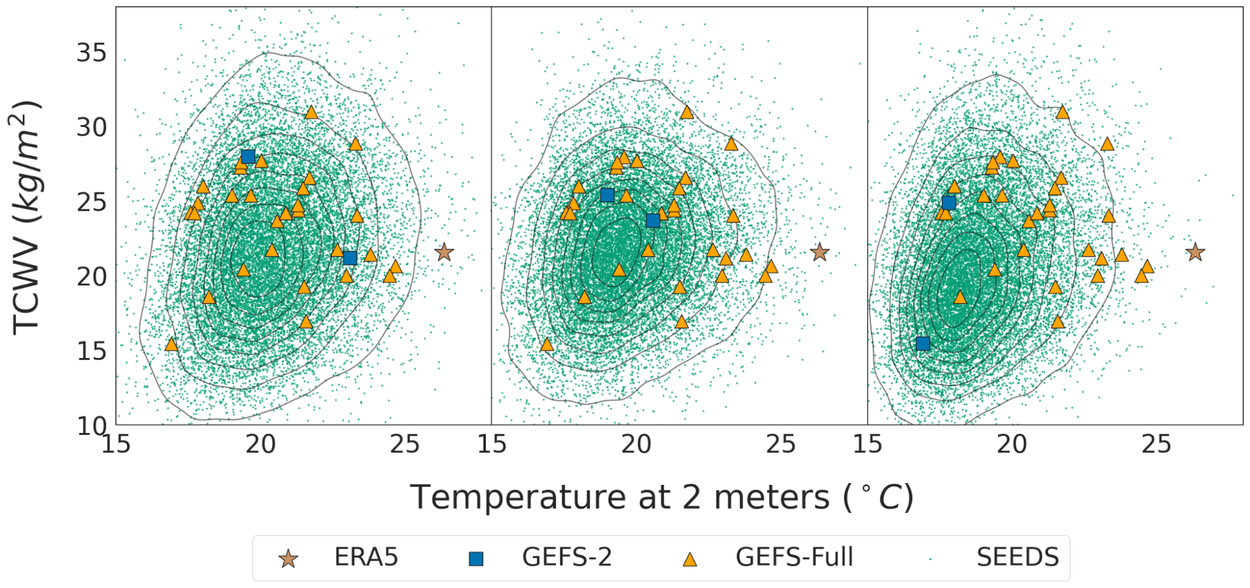
SEEDS peut générer un grand ensemble conditionné à une ou deux prévisions du système opérationnel de prévision météorologique numérique. Les ensembles générés offrent non seulement des prévisions plausibles proches de la météo réelle, mais ils correspondent ou dépassent également les ensembles physiques en termes de mesures de compétence telles que l’**histogramme des rangs**, l’**écart quadratique moyen** (RMSE) et le **score de probabilité continue classé** (CRPS). Plus particulièrement, les ensembles générés attribuent des probabilités plus précises à la queue de la distribution des prévisions, comme les événements météorologiques ±2σ et ±3σ. Plus important encore, le coût de calcul du modèle est négligeable par rapport aux heures de calcul nécessaires aux supercalculateurs pour établir une prévision. Il a un débit de 256 membres d’ensemble (à une résolution de 2°) toutes les 3 minutes sur les instances Google Cloud TPUv3-32 et peut facilement évoluer vers un débit plus élevé en déployant plus d’accélérateurs.
**Génération de prévisions météorologiques plausibles**
L’IA générative est connue pour générer des images et des vidéos très détaillées. Cette propriété est particulièrement utile pour générer des ensembles de prévisions cohérents avec des modèles météorologiques plausibles, ce qui se traduit en fin de compte par la plus grande valeur ajoutée pour les applications en aval. Comme le souligne Lorenz, « Les cartes des [prévisions météorologiques] qu’ils produisent devraient ressembler à de vraies cartes météorologiques ». La figure ci-dessous compare les prévisions de SEEDS à celles du système américain opérationnel de prévision météorologique (Global Ensemble Forecast System, GEFS) pour une date particulière pendant les vagues de chaleur européennes de 2022. Nous comparons également les résultats à ceux d’un modèle gaussien qui prédit la moyenne et l’écart-type univarié de chaque champ atmosphérique à chaque endroit, une approche basée sur les données courante et économe en calcul mais moins sophistiquée. Ce modèle gaussien vise à caractériser la sortie du post-traitement ponctuel, qui ignore les corrélations et traite chaque point de grille comme une variable aléatoire indépendante. Au contraire, une vraie carte météorologique présenterait des structures corrélationnelles détaillées.
Étant donné que SEEDS modélise directement la distribution conjointe de l’état atmosphérique